Writing pipelines¶
In this chapter, you will learn how to write pipelines for Compi. Pipelines are composed of (i) a set of tasks which ones can depend on others and (ii) a set of parameters that the user should provide to run the pipeline.
Once your pipeline is defined, Compi provides you with a powerful multithreaded running environment and a command-line user interface to run it.
The XML file for pipelines¶
Pipelines are defined via an XML file, where tasks and parameters are declared.
Task code are provided in bash by default (you can use other languages). Also,
the pipeline version must be specified in the version tag.
Task dependencies can be defined. For example, a task generate-report
(which creates an HTML summary of an analysis) will depend on analyze-data
(which runs an R script over data) because the file generated by the analysis
task is formatted by the reporting task and thus analyze-data should be run
before generate-report.
A pipeline example¶
Here is pipeline example showing the main features of Compi.
<?xml version="1.0" encoding="UTF-8"?>
<pipeline xmlns="http://www.sing-group.org/compi/pipeline-1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<version>1.0</version>
<params>
<param name="name" shortName="n">Your name</param>
<param name="output" shortName="o">Output file</param>
</params>
<tasks>
<task id="greetings" params="name output">
echo "Hi ${name}" > ${output}
</task>
<task id="bye" after="greetings" params="name output"
interpreter="/usr/bin/perl -e "${task_code}"">
my $filename = $ENV{'output'};
open(my $fh, '>>', $filename) or die "Could not open file '$filename' $!";
print $fh "bye ".$ENV{'name'}."\n"
</task>
</tasks>
<!-- optional part -->
<metadata>
<task-description id="greetings">A task to greet you!</task-description>
<task-description id="bye">A task for saying goodbye!</task-description>
</metadata>
</pipeline>
This small example defines a pipeline with two tasks (greetings and
bye) with two parameters (name and output). The first task simply
writes a greeting with the name provided in the name parameter and saves it
to an output file given in the output parameter. The second task is a perl
task which writes a bye message the the same output file.
Defining pipeline parameters¶
Pipeline parameters are options that the user can define when running a pipeline. Tasks will use these parameters, which will be passed to them as environmental variables. For example, consider the following pipeline:
<?xml version="1.0" encoding="UTF-8"?>
<pipeline xmlns="http://www.sing-group.org/compi/pipeline-1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<version>1.0</version>
<params>
<param name="yourName" shortName="">Your name</param>
</params>
<tasks>
<task id="greetings" params="yourName">
echo "Hi ${yourName}"
</task>
</tasks>
</pipeline>
In this example, the pipeline defines a parameter yourName and the task ()
greetings will make use of it.
The <param> and <flag> elements¶
The <param> and <flag> elements define a parameter of the pipeline.
A <param> can have a default value and can be global, that is, every task
will have access to it without specifying the parameter in the params
attribute of the <task> element (see Defining tasks). <flag> are
a special type of parameters that do not require to specify a value (they
are present or not as environmental variable, but with no concrete value).
<flag> can not have default values.
| Attribute | Description | Mandatory |
|---|---|---|
| name | A name for the parameter. To be compatible with environment variable names, this name can only contain letters, digits, underscores, and can not start with a digit. Parameter names must be unique in the file. | YES |
| shortName | An alternative, and normally shorter, name for the parameter. Parameter short names must be unique in the file. | NO |
| defaultValue | A default value for the parameter. | NO |
| global | A boolean value (“true” or “false”) indicating
that this parameter is global. Global parameters
are always passed to all tasks, without the need
of specifying them in the params attribute
of every task |
NO |
Here it is an example of a parameters section
<?xml version="1.0" encoding="UTF-8"?>
<pipeline xmlns="http://www.sing-group.org/compi/pipeline-1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<version>1.0</version>
<params>
<param name="yourName" shortName="n" global="true" defaultValue="anonymous">Your name</param>
<flag name="sayGoodBye" shortName="g">Do you want to say goodbye?</flag>
</params>
<tasks>
<task id="greetings">
echo "Hi ${yourName}"
</task>
<task id="goodbye"
params="yourName sayGoodBye" if="[ -v sayGoodBye ]"
after="greetings">
echo "Goodbye ${yourName}"
</task>
</tasks>
</pipeline>
Defining tasks¶
Simple tasks: the <task> element¶
Tasks are defined inside the <tasks> element. A <task> element contains
a piece of runnable code (by default in Bash language). Alternatively, the piece
of code can be loaded from the file specified in the src attribute, whose
location is relative to the pipeline XML file. When the task runs, parameters
are passed as environmental variables.
In addition, <task> elements contain the following attributes:
| Attribute | Description | Mandatory |
|---|---|---|
| id | The ID for the task. This must be a valid NCName. | YES |
| after | List of tasks that should end before this task can be started. The list can be separated by whitespaces or commas. | NO |
| params | List of parameters that this task will use. The parameters can not be identified by their shortName. Only global parameters and those indicated here are passed to the task. Values should be separated by whitespaces. | NO |
| interpreter | A command to be run instead of the task code, that can be exploited to interpretate the task code. See Custom interpreters. | NO |
| if | A command to be run just before the task is about run. If the command’s return status is different from 0, the task will be skipped. | NO |
| src | The location of the file (relative to the pipeline XML file) that contains the task code. | NO |
Parallel iterative tasks: the <foreach> element¶
A special type of tasks are foreach tasks. When a foreach task is run, its code is launched several times in parallel over a collection of elements.
There are several types of collection to iterate over (a list of values, a range of numbers, a set of files from a directory, the output lines of a bash command, etc.)
| Attribute | Description | Mandatory |
|---|---|---|
| of | The type of collection to iterate over. There are the following possible values:
|
YES |
| in | The source to take the collection elements to
iterate over. Here you can use pipeline
parameters with ${parameter} as they will
be replaced with they actual value. |
YES |
| as | Name of the loop parameter to use in the task code. | YES |
param example¶
In case you want a param foreach that iterates over all items of a given collection
and the collection is a pipeline parameter, then the in attribute
must be specify this as follows: in="${parameter}".
Try the foreach-items.xml pipeline with:
compi run -o -p foreach-items.xml -- --items_list "A, B, C"
A list foreach works the same way but the items list is a fixed value
file example¶
In case you want a file foreach that iterates over all files under a given
directory and the source directory is a pipeline parameter, then the in attribute
must be specify this as follows: in="${parameter}".
Try the foreach-file-in-data-dir.xml pipeline with:
compi run -o -p foreach-file-in-data-dir.xml -- --data_dir "/path/to/dir"
command example¶
A command foreach has in the in a command whose output lines are the values to
iterate over (each line is an element).
Use this ZIP file to run the pipeline provided with:
compi run -o -p foreach-command.xml -- --file_with_items foreach-command-input.txt
Iteration dependencies between foreach tasks¶
You can define a “iteration dependency” between two foreach tasks, so that
the first iteration of the dependant foreach waits only for the first iteration
of the foreach which is depending on. For example:
<!-- samples is a parameter with values such as
"case-1,case-2,control-1,control-2" -->
<foreach id="preprocess" of="param" in="samples" as="sample">
preprocess.sh ${sample}.csv > ${sample}.preprocessed.csv
</foreach>
<foreach id="analyze" of="param" in="samples" as="sample" after="*preprocess">
analyze.sh ${sample}.preprocessed.csv
</foreach>
Please note the * character in after="*preprocess", which indicates that the iterations
of the second foreach will wait only for their respective iteration of the
first foreach.
Note
It is mandatory that all foreach tasks have the same number of iterations
if you want to establish an “iteration dependency” between them.
Environment variables available for tasks¶
When launching a task, Compi establishes a set of environment variables related with the task
and the Compi execution itself (i.e. the compi run command), plus an additional variable
with the pipeline version (COMPI_PIPELINE_VERSION).
The task-related variables are:
task_id: contains the id of the task being executed.task_code: contains the code (defined in thepipeline.xml) of the task being executed.task_params: contains the list of params associated to the task being executed.task_after: contains the list of tasks that goes before the task being executed.i: in the case offoreachtasks, the iteration value.
The variables related with the Compi execution are:
COMPI_PARAMS_FILECOMPI_DO_NOT_LOG_TASKSCOMPI_UNTIL_TASKCOMPI_MAX_TASKSCOMPI_AFTER_TASKSCOMPI_BEFORE_TASKCOMPI_LOGS_DIRCOMPI_PIPELINE_FILECOMPI_RUNNERS_FILECOMPI_FROM_TASKSCOMPI_SINGLE_TASKCOMPI_LOG_ONLY_TASKSCOMPI_SHOW_STD_OUTSCOMPI_OVERWRITE_LOGS
Defining tasks metadata¶
In order to describe the task objectives, making Compi able to generate user documentation, you can optionally define tasks metadata.
Tasks metadata is defined inside the <metadata> element. A
<task-description> element contains a brief description of the task
objectives. The id attribute indicates the task for which the description
is being provided.
<?xml version="1.0" encoding="UTF-8"?>
<pipeline xmlns="http://www.sing-group.org/compi/pipeline-1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<!-- ... -->
<!-- optional part -->
<metadata>
<task-description id="greetings">A task to greet you!</task-description>
<task-description id="bye">A task for saying goodbye!</task-description>
</metadata>
</pipeline>
Validating a pipeline¶
Run the following command to validate the pipeline.xml file:
compi validate -p pipeline.xml
Viewing the pipeline as a graph¶
Run the following command to export the graph defined by the pipeline.xml pipeline as an image.
compi export-graph -p pipeline.xml -o pipeline.png -f png
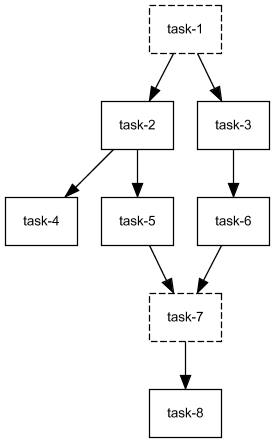
If you want to draw also the task parameters, try options --draw-task-params or --draw-pipeline-params.